架构模式与原则之数据管理篇¶
可扩展性¶
扩展立方(Scale Cube)¶
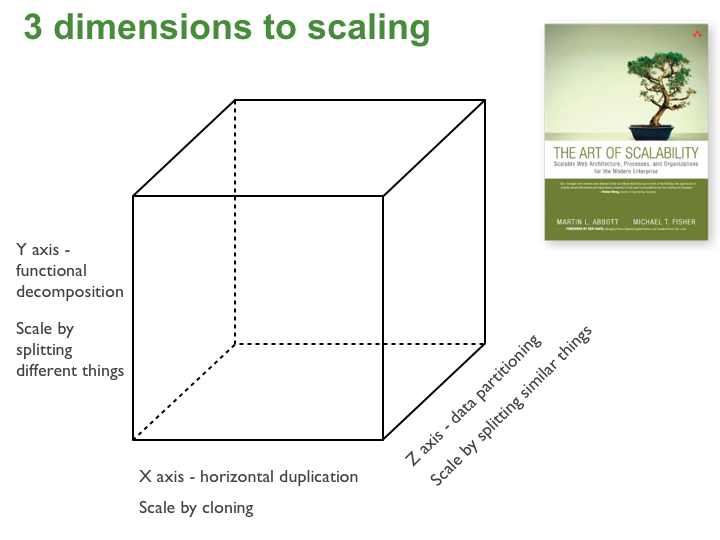
- X轴:水平横向复制和克隆服务与数据(X-Axis: Horizontal Duplication and Cloning of services and data)
- Y轴:功能分解和细分微服务(Y-Axis: Functional Decomposition and Segmentation-Microservices)
- Z轴:沿客户边界做服务和数据分区-分片/单元(Z-Axis: Service and Data Partitioning along Customer Boundaries -Shards/Pods)
水平扩展无状态/有状态应用¶
- 「如何扩展有状态应用」(How to Scale out Stateful App ?)
- CAP 理论(CAP Theorem)
- 一致性级别(Consistency level)
- 严格一致性(Strict consistency)
- 最终一致性(Eventual consistency)
- 分割数据库服务器(Splitting database servers)
- 数据库分片(Database Sharding)
Microservices Data Management¶
混合持久化¶
- 混合持久化原则(Polyglot Persistence principle):每个 service 自己做最佳选择
- 数据完整性与数据一致性(Data integrity and data consistency)
- 每个 service 维护自己的数据(Database-per-service its own data)
- 隔离 service 的数据库(Isolating each service's databases)
- 复制或分区的数据带来挑战(Duplicated or partitioned data challenge)
- 事务管理中的数据一致性问题(Data consistency problems transaction management)
- 拥抱重复数据和最终一致性(Welcome duplicate datas and eventual consistency)
- 接受最终一致性数据(Accept eventual consistency data)
- 能够独立扩展(Ability to scale independently)
- 避免数据库单点故障(Avoid single-point-of-failure of bottleneck databases)
- 事件驱动的架构风格(Event driven architecture style)
模式与原则¶
-
Database-per-Service 模式
- 将单体架构转变为微服务架构(Shifting to the monolithic architecture to microservices architecture)
- 将数据库分解为分布式数据模型(Decomposes database into a distributed data model)
- 快速发展且易于扩展的应用程序(Evolve rapidly and easy to scale applications)
- 更改模式而不产生影响(Schema changes can perform without any impact)
- 独立扩展(Scaling independently)
-
API 组合(Composition)模式
- API 网关模式
- 网关路由模式
- 网关聚合模式
- 网关卸载模式
-
CQRS 模式
- 命令查询责任分离 (CQRS, Command query responsibility segregation)
- 多读少写的方法(Write-less, read-more approaches)
-
事件溯源模式(Event Sourcing)
- 图示
- 累积事件(Accumulate events)
- 将它们聚合为事件序列(Aggregates them into sequence of events)
- 在特定事件点重播(Replay at certain point of events)
-
Saga 模式
- 图示
- 提供事务管理(Provide Transaction management)
- 维护数据一致性(Maintaining data consistency)
-
SAGA 的两种类型
- 编排 :在没有控制点时交换事件(Choreography -when exchanging events happens without points of control)
- 编制:当您有集中式控制器时(Orchestration -when you have centralized controllers)
-
共享型数据库反模式
- 图示
- 共享型数据库是一种典型反模式
- 单一的共享数据库,每个服务访问数据(Single shared database with each service accessing data)
- 单点故障(single-point-of-failure)
- 违背微服务的天性(Against to microservices nature)
数据库分类¶
-
关系数据库(Relational Databases)
- 将数据存储到相关数据表中(Storing data into related data tables)
- 固定模式并使用SQL管理数据(Fixed schema and use SQL to manage data)
- 支持ACID型的事务(Support transactions with ACID)
- 微服务中的混合持久化(Polyglot persistence in microservices)
- 例子:Oracle, MS SQL Server, MySQL, PostgreSQL
-
NoSQL 数据库(NoSQL Databases)
- 不同类型的存储数据(Different types of stored data)
- 易用性、可扩展性、弹性和可用性(Ease-of-use, scalability, resilience and availability)
- 将非结构化数据存储在键值对或JSON文档中(Stores unstructured data in key-value pairs or JSON documents)
- 不提供 ACID 保证(Don't provide ACID guarantees)
-
NoSQL文档数据库(NoSQL Document Databases)
- 在基于JSON的文档中存储和查询数据(Store and query data in JSON-based documents)
- 数据和元数据分层存储(Data and metadata are stored hierarchically)
- 对象映射到应用程序代码(Objects are mapping to the application code)
- 可扩展性,文档数据库分布式友好(Scalability, document databases can distributed very well)
- 内容管理和存储目录:MongoDB 和 Cloudant(Content management and storing catalogs, MongoDB and Cloudant)
-
NoSQL键值数据库(NoSQL Key-Value Databases)
- 数据存储为键值对的集合(Data is storing as a collection of key-value pairs)
- 数据库中的键值组 (Group of key-value in the database)
- 面向会话的应用程序,例如存储客户购物篮数据(Session-oriented applications for example storing customer basket data)
- 例子:Redis, Amazon DynamoDB, OracleNoSQL Database
-
NoSQL 列式数据库(NoSQL Column-based Databases)
- 宽列数据库(Wide-Column Databases)
- 数据存储在列中(Data is stored in columns)
- 更快地访问必要的数据(Access necessary data faster)
- 不要扫描不必要的信息(Don't scanning the unnecessary information)
- 按列独立缩放(Scale by columns independently)
- 数据仓库与大数据处理(Data warehouse and Big Data processing)
- 例子:ClickHouse, Apache Cassandra, Apache HBase or Amazon DynamoDB
-
NoSQL 图式数据库(NoSQL Graph-based Databases)
- 以图形结构存储数据(Stores data in a graph structure)
- 数据实体在节点中连接(Data entities are connected in nodes)
- 导航图形关系(Navigate graph relationships)
- 欺诈检测、社交网络和推荐引擎(Fraud detection, social networks and recommendation engines)
- 例子:OrientDB, Neo4j and Amazon Neptune
如何选择数据库¶
-
Key Point 1 - 考虑“一致性级别”(Consider the "consistency level")
- 我们需要严格的一致性还是最终的一致性?(Do we need Strict Consistency or Eventual Consistency)
- 微服务架构的最终一致性,以获得可扩展性和高可用性(Eventual consistency in microservices architecture in order to gain scalability and high availability)
-
Key Point 2 - 高可扩展性:可满足数百万个请求(High Scalability - accommodate millions of request)
-
Key Point 3 - 高可用:独立的数据中心(-High Availability - separate data center)
- 在决定数据库之前,我们应该检查CAP定理(Before deciding database, we should check the CAP Theorem)
CAP 理论¶
- 1998年由Eric Brewer教授提出(Found in 1998 by Professor Eric Brewer)
- 一致性、可用性和分区容错不能同时实现(Consistency, Availability and Partition Tolerance cannot all be achieved at the same time)
- 分布式系统应该在一致性、可用性和分区容差之间做出牺牲(Distributed systems should sacrifice between consistency, availability and partition tolerance.)
- 只能保证三个概念中的两个:一致性、可用性和分区容差(Can only guarantee two of the three concepts: consistency, availability, and partition tolerance)
-
一致性
- 获取任何读取请求,数据应返回上次更新的值(Consistency-get any read request, the data should return last updated value)
- 必须阻止请求,直到所有副本更新(Must block the request until all replicas update)
-
可用性
- 随时响应请求(Availability-respond to requests at any time)
- 容错,以适应所有请求(fault-tolerance in order to accommodate all requests)
-
分区容错
- 网络分区,位于不同的网络中(Partition Tolerance-network partitioning, located in different networks)
-
同时保持一致性和可用性?
- 如果是分区容差,则应选择可用性或一致性(If Partition Tolerance, either Availability or Consistency should be selected)
- 对于分布式体系结构,分区容差是必须的(Partition Tolerance is a must for distributed architectures)
- 关系数据库防止从不同节点分发数据,NoSQL数据库易于扩展。(Relational databases prevent distribute data from different nodes, NoSQL databases easily scalable.)
- 微服务架构选择具有高可用性的分区容差,并遵循最终的一致性 (Microservices architectures choose Partition Tolerance with High Availability and follow Eventual Consistency)
水平、垂直和功能分区¶
-
水平分区:分片(Horizontal Partitioning - Sharding)
- 每个分区都是一个单独的数据存储(Each partition is a separate data store)
- 所有分区都有相同的模式(All partitions have the same schema)
- 切分并保存数据的特定子集(Shards and holds a specific subset of the data)
- 按字母顺序组织的切分键(Sharding keys organized alphabetically)
- 分片使用分区键分隔不同服务器的负载(Sharding separate the load different servers with partition keys)
-
垂直分区(Vertical Partitioning)
- 也叫行拆分(Row Splitting)
- 保存表的列的子集(Holds a subset of the columns for table)
- 列根据其模式进行划分(Columns are divided according to their pattern)
- 经常访问的列(Frequently accessed columns)
-
功能分区(Functional Partitioning)
- 通过遵循有界上下文或子域对数据进行功能分区(Functionally partitioning data by following the bounded context or subdomains)
- 数据根据有界上下文的使用情况进行隔离(Data is segregated according to usage of bounded contexts)
- 比如,按照职责分解微服务(Like decomposing microservices as per responsibilities)
数据库分片模式¶
- 分片:“一小块或一部分”(Sharding - "a small piece or part")
- 将数据分离为独特的小块(Separation of the data into unique small pieces)
- 提高在微服务中存储数据时的可扩展性(Improve scalability when storing data in microservices)
- 每个碎片都有相同的模式(Each shard has the same schema)
- 分片通过平衡分片之间的工作负载,实现了可扩展性,提高了性能(Shardings enable to scale, improve performance by balancing the workload across shards)
- 使用分区键划分碎片(Dividing into shards with partition keys)
- 案例:Tinder
Cassandra¶
- Cassandra:NoSql 数据库、对等分布式宽列数据库(NoSql Database Peer-to-Peer Distributed Wide Column Database)
- Apache Foundation的分布式数据库,高度可扩展、高性能的分布式数据库(Distributed database from Apache Foundation, highly scalable, high-performance distributed database)
- 无单点故障的高可用性(High availability with no single point of failure)
- 弹性可扩展性(Elastic scalability)
- 灵活的数据存储,方便的数据分发(Flexible data storage, Easy data distribution)
-
Why Cassandra?
- 自动分片功能(Auto-sharding feature)
- 数据切分有助于在节点之间保持数据的分割(Data Sharding helps keep data divided among nodes)
- 分区键设置为 Sensor# 和 Date。(Partition Keys set to Sensor# and Date.)
- microservices数据库的最佳选择(Best choose for microservices database)
- CAP 定理:具有最终一致性的高可用性(CAP Theorem High Availability with Eventual Consistency)
架构设计-数据库分片 Cassandra¶
Microservices Data Management-Cross-Service Queries¶
物化视图模式¶
-
使用场景
- 微服务跨服务查询(Microservices Cross-Service Queries )
- 物化视图模式(Materialized View Pattern)
-
模式描述
- 存储其自己的本地数据副本(Store its own local copy of data)
- 包含数据的非规范化副本(Contains a denormalized copy of the data)
- 数据本地副本作为读取模型(Local copy of data as a Read Model)
- 购物车微服务包含生产和定价微服务的数据的非规范化副本(Shopping Basket microservice contains a denormalized copy of the data which product and pricing microservices)
- 消除了同步跨服务调用(Eliminates the synchronous cross-service calls)
-
模式缺点
- 如何以及何时更新非规范化数据?(How and when the denormalized data will be updated?)
- 数据源是其他微服务(Source of data is other microservices)
- 原始数据更改时,它应该更新为sc microservices(When the original data changes. it should update into sc microservices)
- 发布事件并使用订阅者微服务(Publish an event and consumes from the subscriber microservice)
CQRS 设计模式¶
-
概念
- 命令和查询职责分离(Command and Query Responsibility Segregation)
- 当应用程序既需要处理复杂的连接查询,也需要执行CRUD操作(Applications need both working for complex join queries and also perform CRUD operations)
- 读写数据库有不同的方法(Reading and writing database has different approaches)
- 使用 NoSql 读取和使用关系数据库执行crud操作(Using no-sql for reading and using relational database for crud operations)
- 阅读激励型应用(Read-incentive application)
- 命令执行更新数据(Commands performs update data)
- 同时,查询执行读取数据(Queries performs read data)
- 物化视图模式是实现读取数据库的良好示例(Materialized view pattern is good example to implement reading databases)
- 命令应该是基于任务的操作(Commands should be actions with task-based operations)
- 查询从不修改数据库(Queries is never modifying the database)
-
Instagram 数据库架构
- 对用户故事,使用 NoSql Cassandra数据库(Uses no-sql Cassandra database for user stories)
- 对用户信息生物更新,使用关系型 PostgreSQL数据库(Uses relational PostgreSQL database for User Information bio update)
-
如何同步 CQRS 的数据库?
- 图示
- 事件驱动架构(Event-Driven Architecture)
- 使用message broker系统发布更新事件(Publish an update event with using message broker systems)
- 由读取数据库和同步数据使用(Consume by the read database and sync data)
- 读数据库最终与写数据库同步(Read database eventually synchronizes with the write database)
- 应用物化视图模式,从写数据库副本中读取数据库(Read database from replicas of write database with applying Materialized view pattern)
事件溯源模式¶
- 带有事件源模式的 CQRS(CQRS with Event Sourcing Pattern)
- 真相事件数据库来源(Source-of-truth events database)
- 非规范化表的数据物化视图(Materialized views of the data with denormalized tables)
- 使用message broker系统发布更新事件(Publish an update event with using message broker systems)
- 通过读数据库消费数据,同步数据物化视图模式使用(Consume by the read database and sync data Materialized view pattern)
- 读数据库最终与写数据库同步(Read database eventually synchronizes with the write database)
- 更改为数据保存操作(Changing to data save operations)
- 按数据事件的顺序,将所有事件保存到数据库中(Save all events into database with sequential ordered of data events)
- 将每个更改附加到事件的顺序列表中(Append each change to a sequential list of events)
- 事件存储成为数据的真实来源(Event Store becomes the source-of-truth for the data)
- 具有发布事件的发布/订阅模式(Publish/subscribe pattern with publish event)
- 重播事件来生成数据的最新状态(Replay events to build latest status of data)
最终一致性原则¶
- 带有事件源模式的 CQRS(CQRS with Event Sourcing Pattern)
- 适合偏爱 高可用性 而非 即时一致性 的系统
- 在一定时间后变得一致(Become consistent after a certain time)
- 不能保证即时一致性(Does not guarantee instant consistency)
-
考虑 “一致性级别”(Consider the "consistency level")
-
严格一致性(Strict consistency )
- 当我们保存数据时,数据应该立即影响并显示给每个客户端。
- 案例:debit or withdraw on bank account
-
最终一致性(Eventual consistency)
- 基本上当我们写入任何数据时,客户端读取数据需要一些时间。
- 案例:Youtube video counters
-
Instagram 数据库架构¶
- Instagram系统架构:Instagram 故事视图和用户信息(Instagram System:Architecture Instagram Story View and User Information)
- Instagram认为可用性对他们来说更为重要,并认为最终的一致性就足够了(Instagram decided that Availability was more important to them and thought that Eventual Consistency would be sufficient)
- 关系数据库PostgreSql,另一个是 NoSql 数据库Cassandra(Relational database-PostgreSQLand the other is no-sql database Cassandra)
- PostgreSQL 具有“主-从” 架构(PostgreSQL has a "Master-Slave" architecture)
- 使用关系型 PostgreSQL 数据库进行用户信息生物更新(Uses relational PostgreSQL database for User Information bio update)
- 将 NoSql Cassandra数据库用于用户故事、计数器、消息传递(Uses no-sql Cassandra database for user stories, Counters, messaging)
- Cassandra具有自动切分功能(Cassandra has an auto-sharding feature)
CQRS 架构设计案例¶
- 混合持久化(Polyglot Persistence)
- 物化视图模式(Materialized View Pattern)
- CQRS设计模式(CQRS Design Pattern)
- 事件来源模式(Event Sourcing Pattern)
- 最终一致性原则(Eventual Consistency Principle)
Microservices Distributed Transactions¶
Microservices 分布式事务¶
- 跨多个微服务实现事务性操作(Implement transactional operations across several microservices)
- 微服务上polyglot数据库的复杂网络关注点(Complex network concerns with polyglot database on microservices)
- 微服务上的分布式事务管理手动实现(Distributed transaction managements on microservices implement manually)
分布式事务 Saga 模式¶
- 在分布式事务案例中,跨微服务管理数据一致性(Manage data consistency across microservices in distributed transaction cases)
- 创建一组按顺序更新微服务的事务(Create a set of transactions that update microservices sequentially)
- 发布事件以触发下一个事务(Publish events to trigger the next transaction)
- 如果失败,则触发回滚事务(If failed,trigger to rollback transactions)
- 将这些本地事务分组并逐个顺序调用(Grouping these local transactions and sequentially invoking one by one)
Saga模式:编制与编排¶
-
编排 Saga 模式(choreography Saga Pattern)
- 使用发布/订阅原则来协调 sagas(Coordinate sagas with applying publish-subscribe principles)
- 每个微服务都运行自己的本地事务(Each microservices run its own local transaction)
- 发布事件以触发下一个事务(Publish events to trigger the next transaction)
- 当工作流步骤增加,则可能会变得混乱,难以管理事务(Workflow steps increase, then it can become confusing and hard to manage transaction)
- 用来解耦直接依赖关系(Decouple direct dependency)
-
编制 Saga 模式(orchestration Saga Pattern)
- 用集中式控制器微服务来协调 Sagas(Coordinate sagas with a centralized controller microservice)
- 调用 & 按顺序执行本地microservices事务(Invoke to execute local microservices transactions in sequentially)
- 执行saga事务并集中管理它们,如果其中一个步骤失败,则使用补偿事务执行回滚步骤(Execute saga transaction and manage them in centralized way and if one of the step is failed, then executes rollback steps with compensating transactions)
- 适用于包含大量步骤的复杂工作流(Good for complex workflows which includes lots of steps)
发件箱模式¶
- 当API发布事件消息时,它不会直接发送它们(When your API publishes event messages,it doesn't directly send them)
- 消息持久化在数据库表中,作业将事件发布到消息代理系统(The messages are persisted in a database table,a job publish events to message broker system)
- 提供以“发件箱”角色,将事件可靠地发布到表中(Provides to publish events reliably with written to a table in the "outbox"role)
- 事件和写入发件箱表的事件是同一事务的一部分(The event and The event written to the outbox table are part of the same transaction)
-
Why Outbox Pattern
- 使用需要保持一致的关键数据(Working with critical data that need to consistent)
- 需要准确捕获所有请求(Need to accurate to catch all requests)
- 数据库更新和消息发送应该是原子的(The database update and sending of the message should be atomic)
- 提供数据一致性(Provide data consistency)
- 示例:Financial business sale transactions